





















尚看蓝科技自研的视频全结构化引擎是对视频或图片中的人脸、人体、机动车、非机动车进行目标抓拍、识别、属性分析的智能视频分析引擎,支持人脸检索/聚类、人体检索/聚类、人脸人体关联检索/聚类、车辆检索、车牌识别、属性结构化检索等多种功能。
该引擎采用高效开放的架构模式, 用以稳定灵活的支持各种丰富的功能模块:
• 单机主从架构,保证稳定性
• 可扩展插件系统,满足灵活多变定制
• 支持多种推理模型,高效异构计算平台(多种AI芯片)
• 分布式架构,保证系统高可用
人机协同助力建设泛在智能的未来城市
-
人机协同的目标:人机自然交互、共融共创
人机协同包含“交互-融合-共创”三个过程
- 人机协同
-
 人机交互
人机交互 -
 人机融合
人机融合 -
 人机共创
人机共创
-
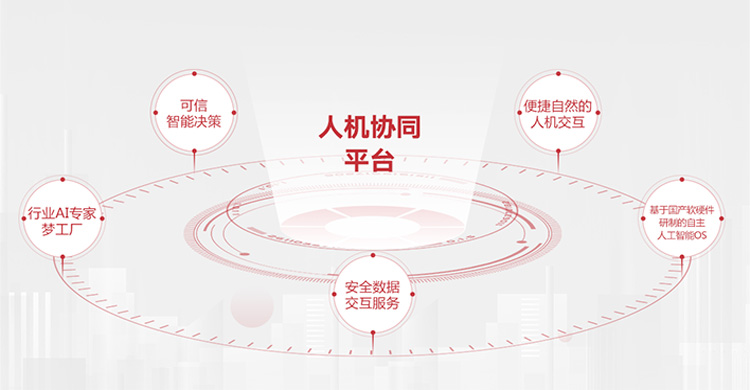
人机协同平台五大特色
人机协同
平台-
行业AI专家
梦工厂 -
可信
智能决策 -
便捷自然的
人机交互 -
基于国产软硬件
研制的自主
人工智能OS -
安全数据
交互服务
-
行业AI专家
-
人机协同:四大核心技术突破
- 多模态数据感知
- 多领域知识推理
- 人机共融共判
- 数据安全共享
-
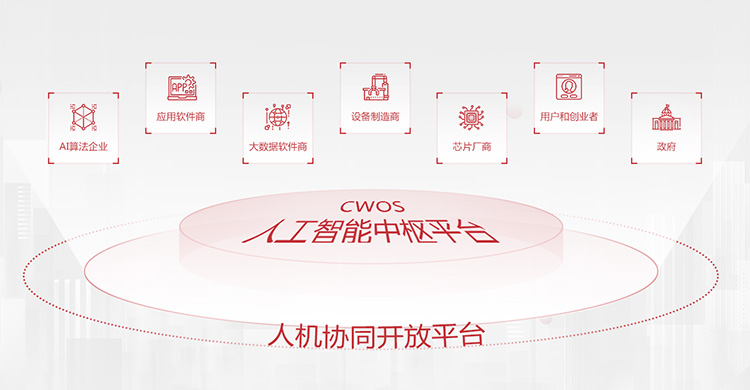
人机协同开放平台
-
 AI算法企业
AI算法企业 -
 应用软件商
应用软件商 -
 大数据软件商
大数据软件商 -
 设备制造商
设备制造商 -
 芯片厂商
芯片厂商 -
 用户和创业者
用户和创业者 -
 政府
政府
-
-
人机协同 助力建设泛在智能的未来城市
-
金融
服务 -
公共
安全 -
智慧
教育 -
智能
商业 -
智能
社区 -
智能
交通 -
其他
社会服务
-
共享基础
资源 -
创新产品
开发 -
上游企业
贯通 -
下游市场
应用
-




